
Theory of Progress
I have spent some time contemplating the question of how technologies advance and here’s my provisional theory-of-progress,
fundamental science » fundamental technologies » applied technologies all take turns to give each other a push forward, in an intervowen web that marches forward with time
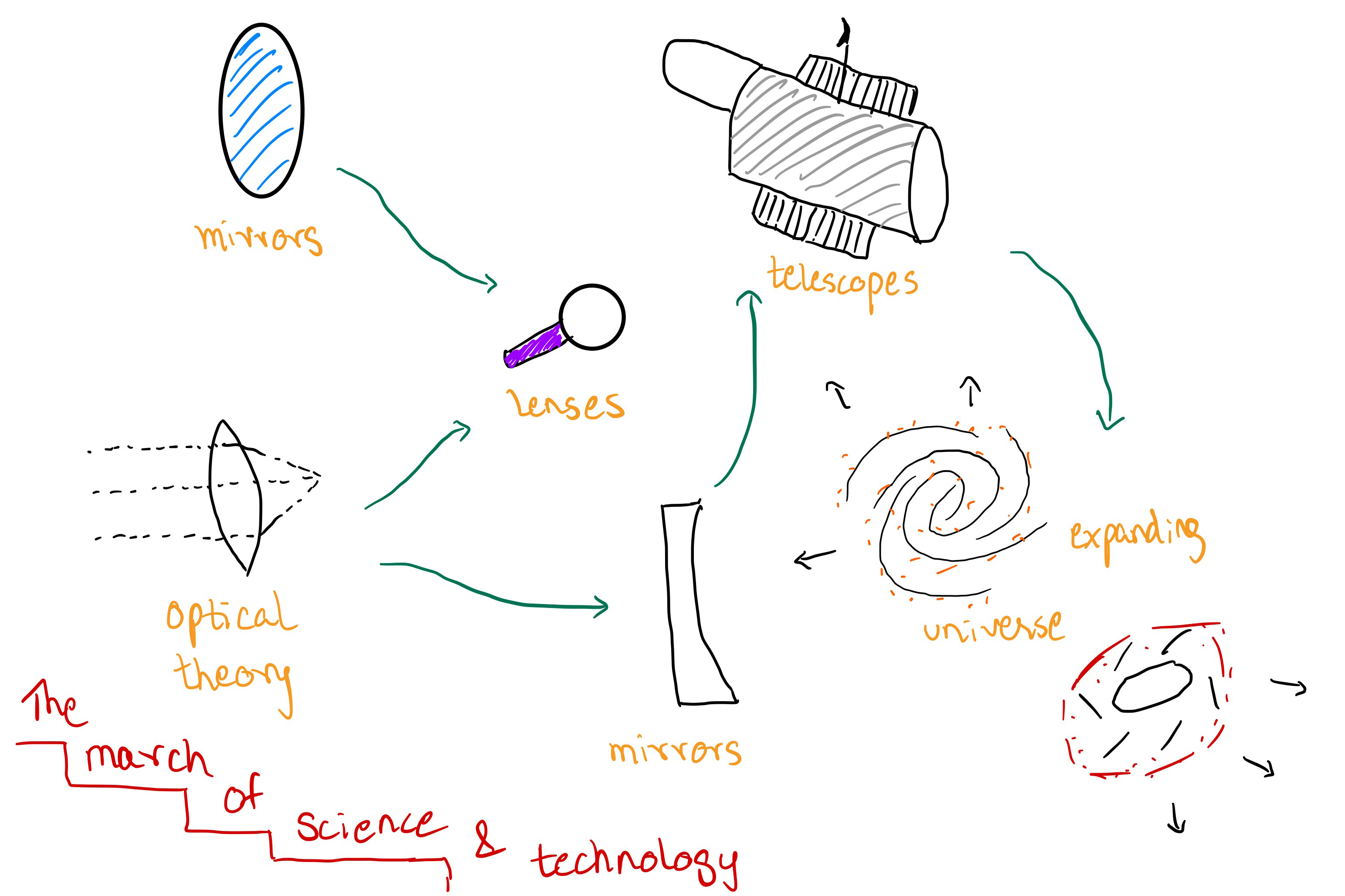
Progress is often non-linear and science and technological breakthroughs often help boost each other forward. We have historically, created fundamental and applied technologies long before understanding the science behind how they work. Wheels, boats, agricultural implements, weapons of warfare (including gunpowder, guns, swords) are all examples of this. In recent history, it is much more often the case that a strong scientific understanding of the laws of physics (and even human behaviour) propels technology forward rather than accidental, creative breakthroughs.
Someone charting the progress of technology can start anywhere on this intervowen chain and traverse nodes forward, to understand how one development prompted another or backward, to understand what developments were pivotal to a breakthrough happening.
Typically starting at the cutting edge, the scientific papers that document today’s newest breakthroughs and recapping the developments that preceded it is exciting. Crucially recent papers also document as yet unsolved challenges. I write these posts hoping that they deliver some practical value, and a neat curated catalogue of these unsolved challenges along with the potential opportunities they could unlock is what I aim to produce.
Source of Truth (or least falsehoods)
One practical concern is the material source of truth to build this timeline. The richest source, and arguably closest to the factual truth is the library of scientific papers humanity has built since the 16th century, which has only really grown exponentially in the last few decades.
While I do intend to refer to different medium of science/technology communication as a starting point, but for deep investigations of this nature, I find comfort in starting at the source. Besides popular communication will more often than not be one step or more behind breakthroughs in the field itself which are often captured in literature.
Tools of Choice
A not-to-be-understated development in the study of literature itself is the development of network traversing tools like Research Rabbit, Connected Papers and Litmaps. These tools quickly and easily allow a user to build a network map of relevant literature. Starting with a paper or an author, you can view all directly cited papers or indirectly related papers (via semantic search) and even papers of the author’s frequent collaborators. My tool of choice for now is ResearchRabbit and I love it for it’s beautiful ability to allow me to traverse from one paper to another with just the right amount of friction. Look out for a future post comparing Research Rabbit to it’s peers.
In addition, I also have begun using the GPT integrated Bing Chat, which allows you to ask questions of your papers (whether PDFs or websites).
Method
It all begins with an interesting paper.
I browse through recent discoveries on different fields, at the moment this is primarily other Substack writers - The Century of Biology , Codon, We all are Robots; Lex Fridman’s podcast, the research blogs of different tech companies, including Google, Meta and Open AI.
One such interesting paper I came across recently was “Solving Rubik's Cube with a Robot Hand” by researchers at OpenAI. The title and numerous riveting videos of the robot hand at work instantly made me curious.
Here are the high level questions I sought to understand next.
What exactly is the problem that has been solved?
Is this the first time a robot hand has solved a Rubik’s cube or is it a performance improvement over previous achievements?
If it is a performance improvement what are the past benchmarks that have been surpassed.
What next?
At what stage of development is this technology? lab/real-world/industrial deployment?
What benchmarks, performance or cost thresholds does it need to surpass to be deployment ready?
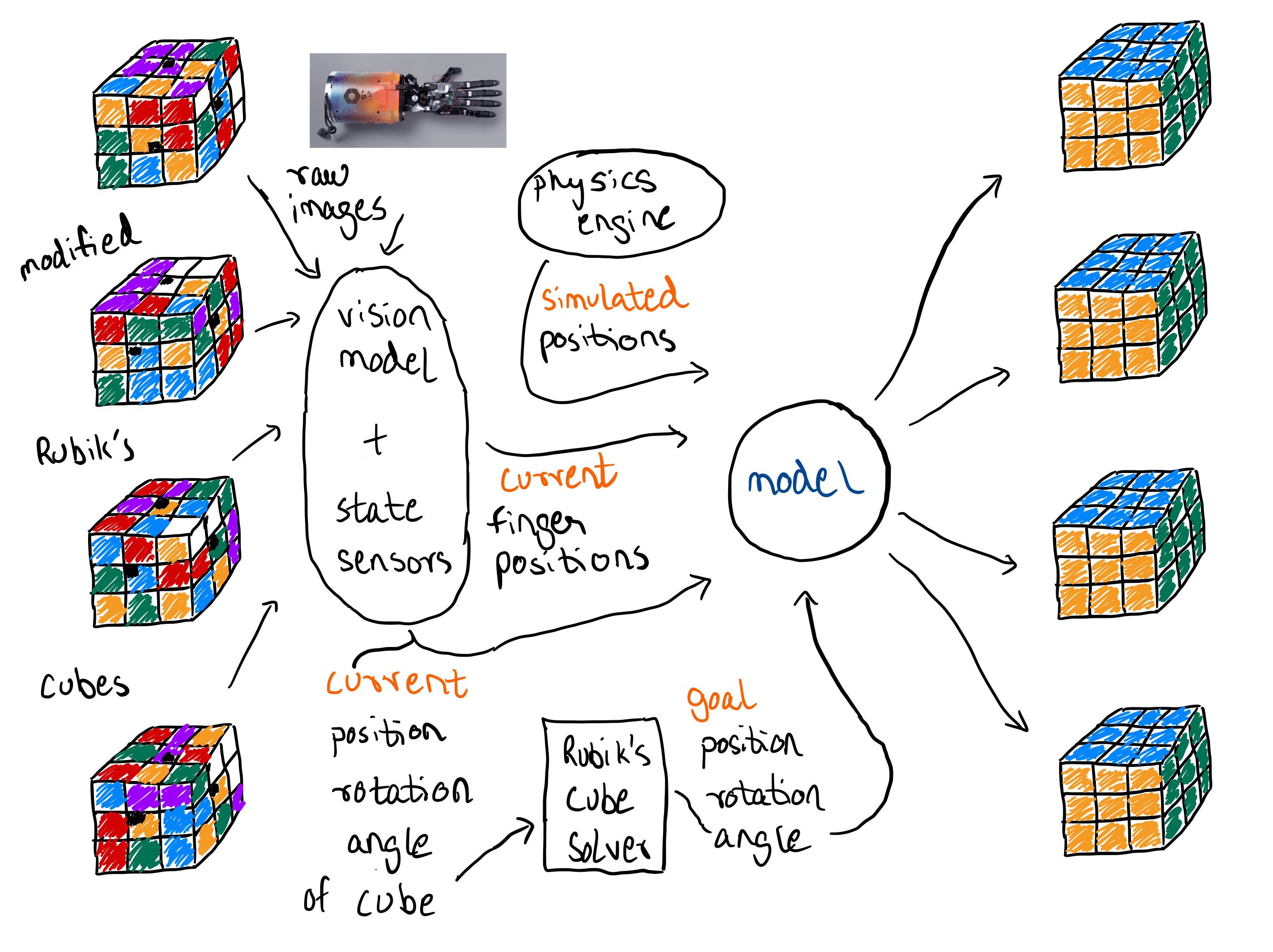
I threw these series of questions (and a number of more specific questions that subsequently came to my mind) at GPT-4 via Bing Chat. After the conversation that ensues I come away with a practical understanding of the breakthrough, its relevance, limitations and knowledge of what to expect next. This dense visual summary captures the essence of the paper. Read on to understand the results
What this isn’t
The Rubik’s cube is a solved problem. This model the authors build in this paper doesn’t need to develop it’s own techniques to solve the Rubik’s cube. It simply uses a program like the Kociemba Solver. This also doesn’t represent a significant leap forward in hardware itself. The Shadow Dextrous Hand used by OpenAI is developed by the Shadow Robot Company. As explained in the next section, this is also not a leap forward in computer vision.
The challenge here is a sensing and control problem. How accurately can the robot hand accurately sense the state (position , orientation (rotation) and face angles of the cube), and then how reliably can it manipulate (flip & rotate) the Rubik’s cube. Sensing is attempted via a combination of a computer vision model and state sensors embedded in the cube itself.
The achievements
When attempting to rely on only computer vision, the model successfully performed a median of 10.5 manipulations and had a 0% success rate at performing 43 manipulations (the number required to successfully solve the cube). With the state sensors, the model had a median success rate of 22 manipulations and successfully solved the cube 20% of the time. This points to a limitation of the model which prevents it from easily generalising to other manipulation tasks simply using video as input.
The innovation
The model is trained via a technique called sim2real, where thousands of diverse simulations of the cube and hand state are generated in a novel approach called Automatic Domain Randomization1, and reinforcement learning is applied. This approach is an innovation for two reasons, 1) Manual Domain Randomization is a tedious time consuming process and only allows for so many distributions of environment parameters, ADR allows for manifold more distribution. 2) This larger set of distributions led to several examples of emergent meta-learning, i.e. the model learning things it wasn’t explicitly taught via simulations. For instance it could recognise that it performed a move incorrectly and was able to reverse it. In another example it realised that a slightly mis-aligned cube face was keeping it from performing the next move. These meta learnings allowed the model to perform some manipulations even with multiple novel challenges which weren’t seen in training, including perturbations, constraints such as the fingers being tied and more.
In next week’s issue, we’ll dive further into part 2 of my method for traversing the knowledge tree - looking at the bigger picture.
This merely means an automatic method for increasing the domain of randomized properties of the hand and cube for e.g. the color, size, weight, texture and more, explained beautifully in this video ,