#4 What came before 'Solving the Cube'
Object Detection > Basic Manipulation > Dextrous Manipulation

In part 2, the bird’s eye view we review past papers by the same authors to allow us to zoom out and understand immediate proximate achievements that led to the solving of the Rubik’s cube. These papers can easily be discovered using tools such as Research Rabbit. The more challenging task is discovering milestones that each paper represents and understanding how they each build on the previous. I am honing QnA techniques used in Bing Chat to simplify this process to read and extract the essence of each paper quicker each time.
Common thread
The dominant breakthrough that connects all the author’s papers is that of Domain Randomization. Domain Randomization essentially builds on the idea that when a model is trained in a simulated environment, physical realism is 1) not needed and 2) it is tremendously difficult to model the real world correctly anyway. Domain randomization trains the model to estimate the position of the cube and learn optimal actions by simulating hundreds of unreal environments. For instance, one where gravity isn’t the earth’s gravity, a variety of colors, textures, masses of the cube and lighting of the environment. With enough variation in the simulated environments, the real world just appears to be another simulated environment to the model. This explains the great success of DR in taking many simulated solutions to the real world, a bottleneck in robotics development.
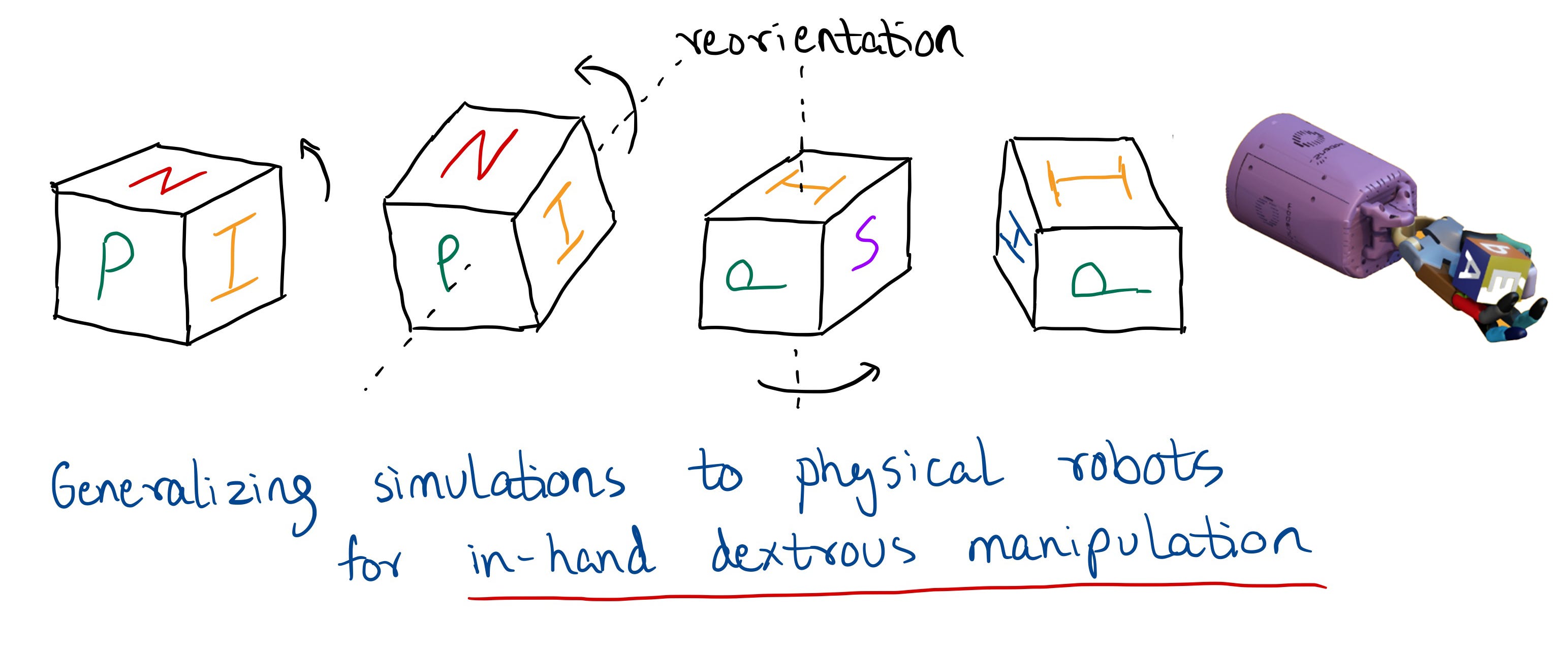
While solving a Rubik’s cube represents a complex challenge, the paper shows that it can be broken down into multiple smaller challenges. Repeatedly re-orienting the cube and rotating one of it’s faces is the fundamental challenge in this paper, a simpler task is just repeatedly re-orienting the cube itself, which the authors tackled in a pre-cursor to this paper. Prior to this work the authors used simpler robotic arms, with 7 Degrees of Freedom as opposed to the 24 DOF of the Shadow Dextrous Hand to do basic manipulation tasks on a 2D surface. Even prior to this the authors used a vision model to predict the position of an object using a vision model and then grasp the same. Each milestone represents breakthrough of different magnitudes, but what that breakthrough is, isn’t always apparent. Read further to understand the four steps preceding “Solving Rubik’s cube with a Robot Hand”.
Object Detection » Basic Manipulation » Dexterous Manipulation » Solving the cube
Object Detection
In the first instance of domain randomization applied to this problem by the authors, “Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World” the task was simply to recognise an object on a table cluttered with other objects and grasp the same. The object detection was done using a Convolutional Neural Network model, which is typical for image recognition problems, and domain randomization was used to show that hundreds of simulated images of the table with objects prove to be a good training environment for the model. The model correctly guesses the object’s position in the real world to within an error of 1.5cm and the robot hand with a non machine learning approach picks up the target object in 38 of 40 trials.
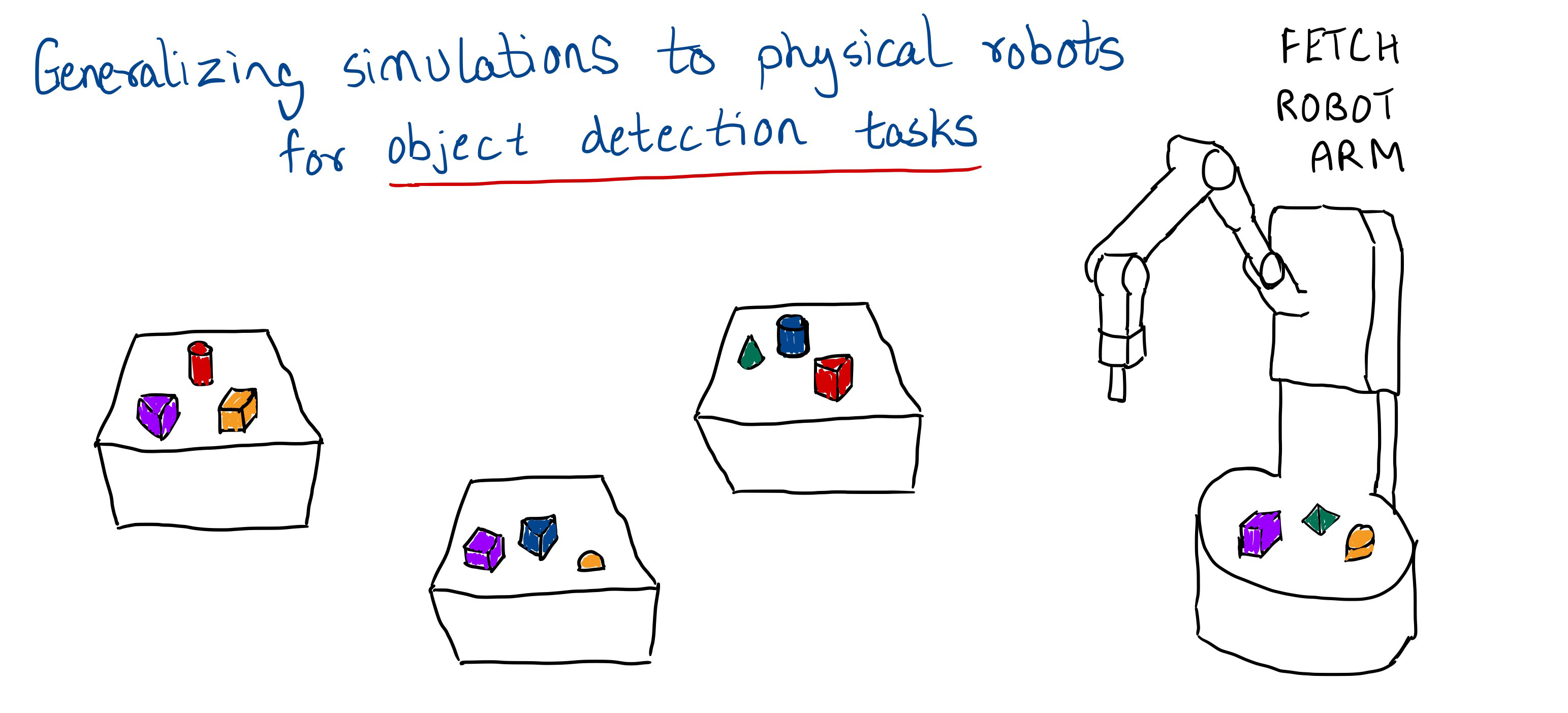
Following this, the authors of “Asymmetric Actor Critic for Image-Based Robot Learning” propose a novel actor-critic algorithm to train a vision-based CNN model for object detection and a reinforcement learning (RL) model for manipulation of a robotic hand with 7 DOF to perform tasks such as picking up, pushing forward and sliding to desired position. The critic network takes the full state of the system as input, while the actor network takes only partial observations as input. This way, the critic can provide better feedback to the actor. This approach shows improvements over a baseline of symmetric (non actor-critic) approaches and thus is used in papers beyond this.
Basic Manipulation
Subsequently, in “Sim-to-Real Transfer of Robotic Control with Dynamics Randomization“ the authors push the boundary even further on basic manipulation tasks described above by using a Reinforcement Learning model with memory , an LSTM. This model when paired with domain randomization , remembers a lot of the simulated environment parameters and this helps it succeed more than 90% of the time at the task of pushing a puck to a desired target.

Dextrous Manipulation
In the pre-cursor, “Learning Dexterous In-Hand Manipulation”, the milestone is moving from simpler robotic hands that allow for simpler manipulation tasks to more complex hands with 24 DOF and replicating the success of sim2real
Solving the Cube
All of this leads to “Solving Rubik’s cube with a Robot Hand” where the breakthrough is “automatic domain randomization” which automates the process of choosing the environment parameters leading to a greater variety of environments and better results over manual domain randomization.

In Conclusion
An alternative to models training in simulations is the “data driven” method where physical trials of the robot in the real world provide enough training data to improve the model. Tesla fully leverages this method to move towards Full Self Driving by gathering raw video feed data from all its millions of cars on the road. We even saw a video of their new robot Optimus being trained with humans gathering real world data. However not all robot tasks in the real world can have this lead period where a human operates the robot for long durations before it learns to operate itself, the cost of physical trials prevents them from being used to train control policies for dozens of different types of manipulations.
Simulated modeled robots can accurately develop control policies for many different types of dexterous manipulations by gathering hundreds of years of experience in days in simulation. Together with domain randomizations they represent a vital way to move forward towards robots that are ready for generalised tasks.